目录
-
学前解说
-
1.1.学前解说
-
- 一、线性模型
-
二、逻辑回归
-
3.1.逻辑回归-原理
-
3.2.逻辑回归-附件
-
3.3.逻辑回归-代码
-
-
三、决策树
-
4.1.CART决策树-模型原理
-
4.2.CART决策树-剪枝原理
-
4.3.CART决策树-代码实现
-
-
四、集成学习
-
5.1.随机森林
-
5.2.AdaBoost
-
5.3.GBDT
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【代码】Lasso回归模型-代码复现
作者 : 老饼
发表日期 : 2026-01-07 08:17:23
更新日期 : 2026-05-21 21:39:08
老饼讲解-简单易懂,干货满满,爽过嗦螺!
本文展示如何自实现坐标下降法求解Lasso,代码是自实现,不调用其它算法包,代码借鉴自sklearn的Lasso包,它的求解结果与sklearn的Lasso包结果一致。
一、自实现Lasso回归(复现sklearn)
本节自写代码具体实现Lasso回归,并检验它的结果与sklearn的是否一致。
1.1. Lasso回归-代码简介
本代码按坐标下降算法流程,自实现Lasso模型,代码扒取自sklearn的Lasso包,是简化后的用于学习的代码,通过本代码可以了解sklearn是如何实现Lasso算法的。
相关原理与算法流程参考:《Lasso回归模型-快速入门》《Lasso回归-算法流程》
1.2. Lasso回归-自实现代码
本代码先简单生成了数据,并设置正则系数,然后使用坐标下降法,逐个系数训练模型,最后输出模型训练结果。具体代码实现如下:
"""
# 本代码展示如何自实现Lasso回归,逻辑扒取自sklearn.linear_model.Lasso
本代码来自《老饼讲解-机器学习》www.bbblearn.com
"""
import numpy as np
# ---------------生成训练数据-----------
x = np.array([[i for i in range(100)],[i*4+3 for i in range(100)]]
).transpose().astype(float) # 生成输入数据X
y = np.dot(x,[2,3]) # 生成输入数据y
# ---------------参数设置---------------
alpha = 0.3 # 正则系数,即lambda
max_iter = 1000 # 最大迭代次数
tol = 1e-4
# --------------数据预处理--------------
# 复制数据
X = x.copy() # 复制X
Y = y.copy() # 复制y
# 调整数据为坐标原点中心的数据
X_offset = np.average(X, axis=0) # x的中心
y_offset = np.average(y, axis=0) # y的中心
X = X - X_offset # 调整x到中心
Y = Y - y_offset # 调整y到中心
# ------------内部参数计算--------------
n_samples, n_features = x.shape # 数据样本数,特征数
alpha_reg = alpha * n_samples # 将 alpha与样本数量对齐
norm_X = np.square(X).sum(axis=0) # 每个X变量的平方和
tol_val = tol*(Y*Y).sum() # 对偶间隙的最小容忍值
# --------------模型训练----------------
w = np.zeros(2) # 初始化解
R = Y - np.dot(X, w) # 初始化残差
for n_iter in range(max_iter): # 循环迭代
last_w = w.copy() # 前一次w的值
for ii in range(n_features): # 逐坐标迭代
R += w[ii] * X[:,ii] # 更新残差:剔除本轮变量
tmp = (X[:,ii]*R).sum() # 计算tmp
w[ii] = (np.sign(tmp) *max(abs(tmp) -alpha_reg,0)/(norm_X[ii])) # 计算最优w
R -= w[ii] * X[:,ii] # 更新残差:添加回本轮变量
#----判断是否达到终止条件------
d_w_max = abs(last_w-w).max() # w的最大变化值
w_max = abs(w).max() # w的最大值
R = Y - np.dot(X,w) # 残差
if (w_max==0.0 or d_w_max/w_max<tol or n_iter==max_iter-1): # 如果满足退出条件
# 计算对偶间隙
XtA = np.dot(X.T, R)
dual_norm_XtA = max(XtA,key=abs)
R_norm2 = (R*R).sum()
if (dual_norm_XtA > alpha_reg):
const = alpha_reg / dual_norm_XtA
A_norm2 = R_norm2 * (const ** 2)
gap = 0.5 * (R_norm2 + A_norm2)
else:
const = 1.0
gap = R_norm2
l1_norm = abs(w).sum()
gap += (alpha_reg * l1_norm - const *(R*Y).sum())
# 如果对偶间隙< tol_val,则终止训练
if gap < tol_val:
break
intercept = y_offset - np.dot(X_offset, w.T) # 计算截距
py = np.dot(x,w) +intercept # 展示模型的预测方法
# -------------打印结果------------------
loss = ((y-py)**2).sum()/(2*x.shape[0])+alpha*(abs(w.sum())) # 计算损失值
print('\n========= 自写Lasso训练结果=========') # 打印结果
print('权重:',w) # 打印模型的权重
print('截距:',intercept) # 打印模型的阈值
print('均方误差:',((y-py)**2).mean()) # 均方误差
print('损失函数loss值:',loss) # 打印损失值
print('迭代次数:',n_iter+1) # 打印迭代次数
print('对偶间隙:',gap/x.shape[0]) # 打印对偶间隙
代码运行结果如下:
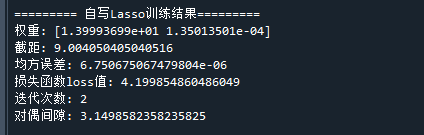
从运行结果,可得到模型表达式:
与《Lasso回归-简单例子》的结果进行对比,可知,同样的数据,该代码与调用sklearn包的结果是一致的。
备注:代码中的退出条件中使用了对偶间隙作为判断条件,该部分笔者就不展开讲解与研究了~
结束语
如果代码中去掉对偶间隙的判断,那代码还算是简单的,无非就是将w逐个迭代到驻点而已,其实我也想去看看对偶间隙部分是怎么回事,找了些资料,后来想想,算了,还是不纠结它了。
上一篇:
【代码】Lasso回归模型-简单例子
下一篇:
【模型】逻辑回归-模型简单- 介绍
 评论
评论
添加评论
