-
学前解说
-
1.1.学前解说
-
- 一、线性模型
-
二、逻辑回归
-
3.1.逻辑回归-原理
-
3.2.逻辑回归-附件
-
3.3.逻辑回归-代码
-
-
三、决策树
-
4.1.CART决策树-模型原理
-
4.2.CART决策树-剪枝原理
-
4.3.CART决策树-代码实现
-
-
四、集成学习
-
5.1.随机森林
-
5.2.AdaBoost
-
5.3.GBDT
-
 老饼讲解:一步一步上手学习
老饼讲解:一步一步上手学习
【原理】Lasso回归模型-快速理解
Lasso回归全称为Least absolute shrinkage and selection operator,是一种可用于筛选变量的模型,本文讲解Lasso回归的模型表达式、损失函数以及Lasso回归的原理与意义,并展示一个Lasso回归的实现例子,通过本文,可以快速了解Lasso回归是什么,模型的原理是什么,以及如何使用Lasso回归来进行筛选变量。
一、什么是Lasso回归
本节讲解Lasso回归模型是什么,包括Lasso回归的表达式、损失函数与求解方法等。
1.1. Lasso回归模型是什么
Lasso回归模型简单来说,就是在线性回归模型的基础上,加入一范正则项,虽然Lasso回归是一个回归模型,但由于它具有系数稀疏化的特点,因此也常用于筛选变量。
Lasso的模型表达式如下:
Lasso回归的损失函数如下:
其中,
:样本个数
:系数个数
:y的预测值
:y的真实值
:惩罚系数,用于调节系数W的惩罚力度
值得注意到,原始的Lasso回归模型是不带阈值的,而它的损失函数则是在MSE均方误差中加入了L1惩罚项。
1.2. Lasso回归模型的阈值
与岭回归模型一样,原始的Lasso回归模型是不带阈值的,因为Lasso回归的目的是对各个w进行惩罚,而阈值b是不需要惩罚的。因此,Lasso回归一般先对数据进行中心化,再进行建模,再反求出阈值,具体如下:
1. 先将数据作中心化转换:
此时, 都是以(0,0)为中心的数据
2. 用训练岭回归模型,得到
3. 训练后再计算阈值b:
即可得到
具体推导可参考岭回归的内容,这里不再重复讲述。
由于Lasso以L1范数作为正则项,无法得到公式解,一般用坐标下降法进行求解,详细流程见下张文章。
二、Lasso回归-系数稀疏化
Lasso是对线性回归、岭回归的改进,它令系数正则化的同时,尽量使系数稀疏化。
2.1. 什么是系数稀疏化
在变量多重共线性的时候,我们往往希望模型在足够有效的前提下,能够使用越少的变量越好,例如,当时,我们希望得到的模型表达式为 ,而不是 ,这种能令部分系数为0的效果,就被称为系数稀疏化,它可以起到简化模型或者筛选变量的作用。
2.2. 为什么Lasso容易让系数稀疏化
岭回归虽然能够抑制系数过大,但它很难得到稀疏系数,而Lasso回归却比较容易得到稀疏系数。下面我们非严谨地解释一下,为什么为什么Lasso回归容易让系数稀疏化。
不妨把损失函数中的误差项记为 ,正则项记为 ,则此时损失函数简记为 ,可证明,损失函数 的最优解必定在 的等高线与 的等高线的切点处取得(这里省略证明):
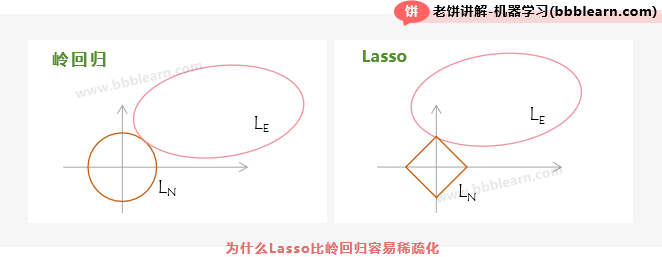
以二维为例,岭回归的正则项是一个圆,要与相切于坐标轴是很难的,反观Lasso的正则项 ,它是一个棱形,要与相切于坐标轴却很容易。因此,岭回归很难得到稀疏系数,而相比之下,LASSO回归更易得到稀疏系数。
正因为LASSO回归容易得到稀疏系数,因此也可作为筛选变量的一种技术,在建模之前,可以先用Lasso回归检测哪些变量的系数为0,然后把系数为0的变量去掉再进行建模。
四、 如何实现一个Lasso回归模型
在sklearn中要实现Lasso回归,只需调用linear_model.Lasso就可以,具体代码如下:
"""
本代码展示一个简单的sklearn实现LASSO回归的Demo代码
本代码来自《老饼讲解-机器学习》www.bbblearn.com
"""
from sklearn.linear_model import Lasso
import numpy as np
# -----------生成数据-------------
x1 = np.arange(0,100) # 生成x1
x2 = x1*4+3 # 生成x2,这里的x2与x1是线性相关的
x = np.concatenate((x1.reshape(-1, 1),x2.reshape(-1, 1)),axis=1) # 将x1,x2合并作为x
y = x.dot([2,3]) # 生成y
# ----------Lasso模型训练----------
alpha = 0.3 # 设置正则项系数alpha
clf = Lasso(alpha=alpha,fit_intercept=True,max_iter=1000) # 初始化Lasso回归模型
clf.fit(x,y) # 用数据训练模型
py = clf.predict(x) # 预测
print('系数:',clf.coef_) # 打印模型系数
print('阈值:',clf.intercept_) # 打印模型阈值运行结果如下:

代入模型表达式,可得到模型为:
可以看到,第二个变量的系数已接近于0,说明第二个变量在模型中是可去除的,这就是Lasso回归的好处,在线性相关时,其中一个变量的系数会趋于0。
总结
Lasso回归就是在线性回归的基础上,在损失函数MSE中加入了L1正则项,这样可以用于惩罚系数过大,它与岭回归类似,但是它更容易得到稀疏解,但也正因为它加入了L1正则项,所以没有公式解,一般靠坐标下降法来求解。
 评论
评论
